面向对象高级一
权限修饰符
| 修饰符 | 在本类中 | 同一个包下的其他类里 | 任意包下的子类里 | 任意包下的任意类里 |
|---|---|---|---|---|
| private | √ | |||
| 缺省 | √ | √ | ||
| protected | √ | √ | √ | |
| public | √ | √ | √ | √ |
说明: protected修饰的方法可以在任意包下的子类里访问, 但是这个子类对应的实例是不能访问的.
方法重写规则
- 使用@Override注解可以帮忙检查是否书写错误
- 重写父类方法, 子类方法访问权限大于等于父类该方法权限(public>protected>缺省)
- 重写方法返回值, 必须与被重写方法的返回值类型一样, 或者范围更小
- 私有方法, 静态方法不能被重写
个人理解这些规则的目的是为了兼容性和安全性.
子类构造器
子类的全部构造器, 都会默认先调用父类的无参构造器(super()), 再执行自己. 如果父类没有无参构造器, 必须在子类构造器第一行手写super(…) 调用父类的有参构造器.
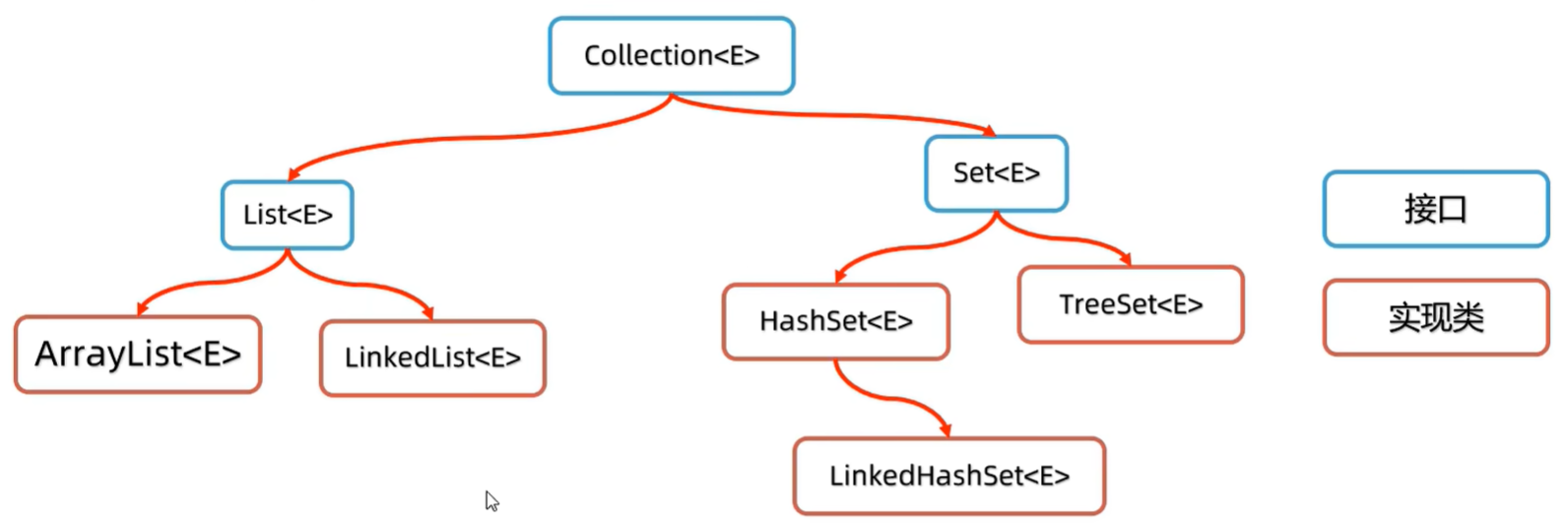
集合框架
-
如果希望记住元素的添加顺序,需要存储重复的元素,又要频繁的根据索引查询数据?
用ArrayList集合(有序、可重复、有索引),底层基于数组的。(常用)
-
如果希望记住元素的添加顺序,且增删首尾数据的情况较多?
用LinkedList集合(有序、可重复、有索引),底层基于双链表实现的。
-
如果不在意元素顺序,也没有重复元素需要存储,只希望增删改查都快?
用HashSet集合(无序,不重复,无索引),底层基于哈希表实现的。 (常用)
-
如果希望记住元素的添加顺序,也没有重复元素需要存储,且希望增删改查都快?
用LinkedHashSet集合(有序,不重复,无索引), 底层基于哈希表和双链表。
-
如果要对元素进行排序,也没有重复元素需要存储?且希望增删改查都快?
用TreeSet集合,基于红黑树实现。
Collection接口下有list和set接口, list有序 可重复 有索引, set无序,不重复,无索引.
Collection接口
特有方法
- add(): 添加元素
- clear(): 清除集合的元素
- isEmpty(): 判断集合是否为空
- Size(): 获取集合的大小
- contains(Object obj): 判断是否包含
- remove(Object obj): 删除元素,有多个删除第一个
- toArray(): 将集合转为数组
- addAll(Collection): 将一个集合的全部数据倒入到另一个集合中去
1 Collection<String> c = new ArrayList<>(); // 多态写法
2 // 1.public boolean add(E e):添加元素, 添加成功返回true。
3 c.add("java1");
4 c.add("java1");
5 c.add("java2");
6 c.add("java2");
7 c.add("java3");
8 System.out.println(c);
9
10 // 2.public void clear():清空集合的元素。
11 //c.clear();
12 //System.out.println(c);
13
14 // 3.public boolean isEmpty():判断集合是否为空 是空返回true,反之。
15 System.out.println(c.isEmpty()); // false
16
17 // 4.public int size():获取集合的大小。
18 System.out.println(c.size());
19
20 // 5.public boolean contains(Object obj):判断集合中是否包含某个元素。
21 System.out.println(c.contains("java1")); // true
22 System.out.println(c.contains("Java1")); // false
23
24 // 6.public boolean remove(E e):删除某个元素:如果有多个重复元素默认删除前面的第一个!
25 System.out.println(c.remove("java1"));
26 System.out.println(c);
27
28 // 7.public Object[] toArray():把集合转换成数组
29 //泛型的原因在运行时会擦除, 不能确保集合里都是字符串, 所以是Object数组.
30 Object[] arr = c.toArray();
31 System.out.println(Arrays.toString(arr));
32
33 //这种方式必须确保集合里面都是字符串
34 String[] arr2 = c.toArray(new String[c.size()]);
35 System.out.println(Arrays.toString(arr2));
36
37 System.out.println("--------------------------------------------");
38 // 把一个集合的全部数据倒入到另一个集合中去。
39 Collection<String> c1 = new ArrayList<>();
40 c1.add("java1");
41 c1.add("java2");
42 Collection<String> c2 = new ArrayList<>();
43 c2.add("java3");
44 c2.add("java4");
45 c1.addAll(c2); // 就是把c2集合的全部数据倒入到c1集合中去。
46 System.out.println(c1);
47 System.out.println(c2);
遍历
1.使用迭代器, iterator()方法返回一个迭代器
迭代器方法:
- boolean hasNext() 询问当前位置是否有元素存在
- E next() 获取当前位置的元素, 并同时将迭代器对象指向下一个元素处.
1 Collection<String> c = new ArrayList<>();
2 c.add("赵敏");
3 c.add("小昭");
4 c.add("素素");
5 // c.add("灭绝");
6 System.out.println(c);
7 // c = [赵敏, 小昭, 素素]
8 // it
9
10 // 使用迭代器遍历集合
11 // 1、从集合对象中获取迭代器对象。
12 Iterator<String> it = c.iterator();
13// System.out.println(it.next());
14// System.out.println(it.next());
15// System.out.println(it.next());
16// System.out.println(it.next());
17 // System.out.println(it.next()); // 出现异常的
18
19 // 2、我们应该使用循环结合迭代器遍历集合。
20 while (it.hasNext()){
21 String ele = it.next();
22 System.out.println(ele);
23
24 }
2.使用for循环, 本质是迭代器遍历集合. 也可以用来遍历数组
1 Collection<String> c = new ArrayList<>();
2 c.add("赵敏");
3 c.add("小昭");
4 c.add("素素");
5 c.add("灭绝");
6 System.out.println(c);
7 // c = [赵敏, 小昭, 素素, 灭绝]
8 // ele
9
10 // 使用增强for遍历集合或者数组。
11 for (String ele : c) {
12 System.out.println(ele);
13 }
14
15 String[] names = {"迪丽热巴", "古力娜扎", "稀奇哈哈"};
16 for (String name : names) {
17 System.out.println(name);
18 }
3.Lambda表达式遍历
1 Collection<String> c = new ArrayList<>();
2 c.add("赵敏");
3 c.add("小昭");
4 c.add("殷素素");
5 c.add("周芷若");
6 System.out.println(c);
7 // [赵敏, 小昭, 殷素素, 周芷若]
8 // s
9
10 // default void forEach(Consumer<? super T> action): 结合Lambda表达式遍历集合:
11 //forEach是Iterable的方法, Collection是Iterable的子接口.
12 c.forEach(new Consumer<String>() {
13 @Override
14 public void accept(String s) {
15 System.out.println(s);
16 }
17 });
18
19 //@FunctionalInterface函数式注解, 可以将匿名内部类替换为Lambda表达式.
20 c.forEach((String s) -> {
21 System.out.println(s);
22 });
23
24 c.forEach(s -> {
25 System.out.println(s);
26 });
27
28 //只有一行可以去掉大括号
29 c.forEach(s -> System.out.println(s) );
30
31 //函数引用, 前后参数一样的情况下可以用方法引用. System.out这个对象调用println这个方法.
32 c.forEach(System.out::println );
List接口
特有方法
- add(int index, E element): 指定位置插入元素, 如果位置已有元素也不会覆盖, 就是中间插, 别的挤旁边了.
- E remove(int index): 删除指定位置的元素, 返回被删除的值
- E set(int index, E element): 修改指定索引处的元素, 返回被修改的元素
- E get(int index): 返回指定索引处的元素
1 // 1.创建一个ArrayList集合对象(有序、可重复、有索引)
2 List<String> list = new ArrayList<>(); // 一行经典代码
3 list.add("蜘蛛精");
4 list.add("至尊宝");
5 list.add("至尊宝");
6 list.add("牛夫人");
7 System.out.println(list); // [蜘蛛精, 至尊宝, 至尊宝, 牛夫人]
8
9 // 2.public void add(int index, E element): 在某个索引位置插入元素。
10 list.add(2, "紫霞仙子");
11 System.out.println(list);
12
13 // 3.public E remove(int index): 根据索引删除元素,返回被删除元素
14 System.out.println(list.remove(2));
15 System.out.println(list);
16
17 // 4.public E get(int index): 返回集合中指定位置的元素。
18 System.out.println(list.get(3));
19
20 // 5.public E set(int index, E element): 修改索引位置处的元素,修改成功后,会返回原来的数据
21 System.out.println(list.set(3, "牛魔王"));
22 System.out.println(list);
遍历方式
1.Collection支持的它也支持
2.for循环遍历(索引遍历)
1 List<String> list = new ArrayList<>();
2 list.add("糖宝宝");
3 list.add("蜘蛛精");
4 list.add("至尊宝");
5
6 //(1)for循环
7 for (int i = 0; i < list.size(); i++) {
8 // i = 0 1 2
9 String s = list.get(i);
10 System.out.println(s);
11 }
12
13 //(2)迭代器。
14 Iterator<String> it = list.iterator();
15 while (it.hasNext()) {
16 System.out.println(it.next());
17 }
18
19 //(3)增强for循环(foreach遍历)
20 for (String s : list) {
21 System.out.println(s);
22 }
23
24 //(4)JDK 1.8开始之后的Lambda表达式
25 list.forEach(s -> {
26 System.out.println(s);
27 });
ArrayList的底层原理
特点: 基于数组实现
- 查询速度快(是根据索引查询数据快): 查询数据通过地址值和索引定位, 查询任意数据耗时相同
- 删除效率低: 可能需要把后面很多的数据进行前移
- 添加效率极低:可能需要把后面很多数据后移, 或者需要对数组扩容
底层原理
- 利用无参构造创建ArrayList时, 底层创建一个长度为0的数组
- 添加第一个元素时, 底层创建一个新的长度为10的数组
- 存满时, 扩容至1.5倍
- 如果一次添加多个数据, 同时即使扩容1.5被也放不下, 那么新创建数组的长度就以刚刚装满为准.
实用场景
适合: 查询数据较多, 或者数据量不是很大时
不适合: 数据量大的同时又需要频繁进行增删操作.
LinkedList底层原理
特点: 基于双链表实现
查询慢, 增删相对较快. 对首尾元素进行增删改查的速度是极快的.
新增方法
- addFirst(E e): 开头插入元素, push一样
- addLast(E e): 追加元素至末尾, pop一样
- E get First(): 返回第一个元素
- E get Last(): 返回最后一个元素
- E removeFirst(): 从列表中删除并返回第一个元素
- E removeLast(): 从列表中删除并返回最后一个元素
应用场景
设计队列:
1 // 1、创建一个队列。
2 LinkedList<String> queue = new LinkedList<>();
3 // 入队
4 queue.addLast("第1号人");
5 queue.addLast("第2号人");
6 queue.addLast("第3号人");
7 queue.addLast("第4号人");
8 System.out.println(queue);
9 // 出队
10 System.out.println(queue.removeFirst());
11 System.out.println(queue.removeFirst());
12 System.out.println(queue.removeFirst());
13 System.out.println(queue);
14 System.out.println("--------------------------------------------------");
设计栈:
1 // 2、创建一个栈对象。
2 LinkedList<String> stack = new LinkedList<>();
3 // 压栈(push)
4 stack.push("第1颗子弹");
5 stack.push("第2颗子弹");
6 stack.push("第3颗子弹");
7 stack.push("第4颗子弹");
8 System.out.println(stack);
9 // 出栈(pop)
10 System.out.println(stack.pop());
11 System.out.println(stack.pop());
12 System.out.println(stack);
Set接口
set下的实现类增删改查都快.
- HashSet: 无序, 不重复, 无索引
- LinkedHashSet: 有序(按添加顺序), 不重复, 无索引
- TreeSet: 排序(默认升序), 不重复, 无索引
set几乎没有新增的功能, 都是用Collection的.
1 // 1、创建一个Set集合的对象
2 //Set<Integer> set = new HashSet<>(); // 创建了一个HashSet的集合对象 一行经典代码 HashSet: 无序 不重复 无索引
3 Set<Integer> set = new LinkedHashSet<>(); // 有序 不重复 无索引
4// Set<Integer> set = new TreeSet<>(); // 可排序(升序) 不重复 无索引
5 set.add(666);
6 set.add(555);
7 set.add(555);
8 set.add(888);
9 set.add(888);
10 set.add(777);
11 set.add(777);
12 System.out.println(set);
HashSet底层原理
Java中每个对象都有个哈希值, 使用hashCode方法返回一个哈希值, 范围是-21亿多到+21亿多. 不同的对象哈希值有可能会相同(哈希碰撞)
HashSet是基于哈希表实现的, 哈希表是一种增删改查性能都较好的数据结构
在Jdk8之前哈希表=数组+链表; 在Jdk8开始, 哈希表=数组+链表+红黑树.
jdk8之前:
- 创建一个默认长度16的数组, 默认加载因子0.75, 数组名table
- 使用元素的哈希值对数组长度求余, 计算存入位置
- 如果该位置为null, 直接存入
- 如果该位置不为null, 调用equals方法比较是否相等, 不相等则存入数组(jdk8之前新元素存入数组老元素挂下面; jdk8开始新元素挂老元素下面)
- 当占满了16(数组长度)*0.75(加载因子)个位置, 数组就开始扩容, 扩大约两倍, 防止链表过长影响查询效率.
jdk8开始, 当链表长度超过8, 同时数组长度>=64时, 自动将链表转成红黑树.
需了解的树结构
- 二叉树: 度小于等于2的数
- 二叉搜索(查找)树: 小的放左边, 大的放右边, 一样的不放. 可能会出现变成链表的情况.
- 平衡二叉树: 满足查找二叉树规则情况下, 使这棵树尽量变矮.
- 红黑树: 可以自平衡的二叉树
HashSet去重复
要让HashSet将内容一样的两个对象认为是重复的去重的话, 需要重写hashCode和equals方法.
1 // 只要两个对象内容一样就返回true
2 @Override
3 public boolean equals(Object o) {
4 if (this == o) return true;
5 if (o == null || getClass() != o.getClass()) return false;
6 Student student = (Student) o;
7 return age == student.age && Double.compare(student.height, height) == 0 && Objects.equals(name, student.name);
8 }
9
10 // 只要两个对象内容一样,返回的哈希值就是一样的。
11 @Override
12 public int hashCode() {
13 // 姓名 年龄 身高计算哈希值的
14 return Objects.hash(name, age, height);
15 }
LinkedHashSet底层原理
基于哈希表(数组, 链表, 红黑树)实现. 每个元素额外多了一个双链表机制记录它前后元素的位置. 所以可以有序. 但额外占内存
TresSet
底层是基于红黑树实现的排序
- 对于数值, 按数值本身大小排序
- 对于字符串, 按首字母编号升序排序
- 对于自定义类型, 默认无法直接排序
自定义排序规则
方式一: 自定义类实现Comparable接口, 重写compareTo方法
1 @Override
2 public int compareTo(Student o) {
3 // 如果认为左边对象大于右边对象返回正整数
4 // 如果认为左边对象小于右边对象返回负整数
5 // 如果认为左边对象等于右边对象返回0
6 // 需求:按照年龄升序排序、
7 return this.age - o.age;
8 }
方式二: 调用TreeSet有参构造器, 设置Comparator对象
(Double.compare比较小数, 返回整数.)
1 Set<Integer> set1 = new TreeSet<>();
2 set1.add(6);
3 set1.add(5);
4 set1.add(5);
5 set1.add(7);
6 System.out.println(set1);
7
8 // TreeSet就近选择自己自带的比较器对象进行排序
9// Set<Student> students = new TreeSet<>(new Comparator<Student>() {
10// @Override
11// public int compare(Student o1, Student o2) {
12// // 需求:按照身高升序排序
13// return Double.compare(o1.getHeight() , o2.getHeight());
14// }
15// });
16 Set<Student> students = new TreeSet<>(( o1, o2) -> Double.compare(o1.getHeight() , o2.getHeight()));
17 students.add(new Student("蜘蛛精",23, 169.7));
18 students.add(new Student("紫霞",22, 169.8));
19 students.add(new Student("至尊宝",26, 165.5));
20 students.add(new Student("牛魔王",22, 183.5));
21 System.out.println(students);
注意
- 这里既规定了大小, 也规定了相等, 而相等是不存放的.
- 如果两者都规定了, TreeSet就近选择自己自带的比较器对象进行排序
- 默认是升序, 如果想要降序只需要将返回值相应地设反即可(大就返回负数).
集合并发修改异常问题
使用集合的remove方法删除的是第一个元素, 这导致出现错位的问题.
解决方案: 1. 使用迭代器自带的删除方法
2. for循环倒着删除, 或者每次删除后下标减1.
1public static void main(String[] args) {
2 List<String> list = new ArrayList<>();
3 list.add("王麻子");
4 list.add("小李子");
5 list.add("李爱花");
6 list.add("张全蛋");
7 list.add("晓李");
8 list.add("李玉刚");
9 System.out.println(list);
10 // [王麻子, 小李子, 李爱花, 张全蛋, 晓李, 李玉刚]
11
12 // 需求:找出集合中全部带“李”的名字,并从集合中删除。
13// Iterator<String> it = list.iterator();
14// while (it.hasNext()){
15// String name = it.next();
16// if(name.contains("李")){
17// list.remove(name);
18// }
19// }
20// System.out.println(list);
21
22 // 使用for循环遍历集合并删除集合中带李字的名字
23 // [王麻子, 小李子, 李爱花, 张全蛋, 晓李, 李玉刚]
24 // [王麻子, 李爱花, 张全蛋, 李玉刚]
25 // i
26// for (int i = 0; i < list.size(); i++) {
27// String name = list.get(i);
28// if(name.contains("李")){
29// list.remove(name);
30// }
31// }
32// System.out.println(list);
33
34 System.out.println("---------------------------------------------------------");
35 // 怎么解决呢?
36 // 使用for循环遍历集合并删除集合中带李字的名字
37 // [王麻子, 小李子, 李爱花, 张全蛋, 晓李, 李玉刚]
38 // [王麻子, 张全蛋]
39 // i
40 for (int i = 0; i < list.size(); i++) {
41 String name = list.get(i);
42 if(name.contains("李")){
43 list.remove(name);
44 i--;
45 }
46 }
47 System.out.println(list);
48 // 倒着去删除也是可以的。
49
50 // 需求:找出集合中全部带“李”的名字,并从集合中删除。
51 Iterator<String> it = list.iterator();
52 while (it.hasNext()){
53 String name = it.next();
54 if(name.contains("李")){
55 // list.remove(name); // 并发修改异常的错误。
56 it.remove(); // 删除迭代器当前遍历到的数据,每删除一个数据后,相当于也在底层做了i--
57 }
58 }
59 System.out.println(list);
60
61 // 使用增强for循环遍历集合并删除数据,没有办法解决bug.
62// for (String name : list) {
63// if(name.contains("李")){
64// list.remove(name);
65// }
66// }
67// System.out.println(list);
68
69// list.forEach(name -> {
70// if(name.contains("李")){
71// list.remove(name);
72// }
73// });
74// System.out.println(list);
75 }
Collections工具类
可变参数, 可以不传也可以传多个(type… var), 在方法内部就是一个数组, 支持数组的方法.
关于<? super T>:理解Java泛型的复杂写法<? super T>,<? extend T> , 大概<? super T>代指T及T的父类; <? extend T>指T及T的子类.
-
1public static <T> boolean addAll(Collection<? super T> c, T...elements):为集合批量添加数据 -
1public static void shuffle(List<?> list):打乱List集合中的元素顺序。 -
1public static <T> void sort(List<T> list):对List集合中的元素进行升序排序。 -
1public static <T> void sort(List<T> list, Comparator<? super T> c): 对List集合中元素,按照比较器对象指定的规则进行排序
1 // 1、public static <T> boolean addAll(Collection<? super T> c, T...elements):为集合批量添加数据
2 List<String> names = new ArrayList<>();
3 Collections.addAll(names, "张三", "王五", "李四", "张麻子");
4 System.out.println(names);
5
6 // 2、public static void shuffle(List<?> list):打乱List集合中的元素顺序。
7 Collections.shuffle(names);
8 System.out.println(names);
9
10 // 3、 public static <T> void sort(List<T> list):对List集合中的元素进行升序排序。
11 List<Integer> list = new ArrayList<>();
12 list.add(3);
13 list.add(5);
14 list.add(2);
15 Collections.sort(list);
16 System.out.println(list);
17
18 List<Student> students = new ArrayList<>();
19 students.add(new Student("蜘蛛精",23, 169.7));
20 students.add(new Student("紫霞",22, 169.8));
21 students.add(new Student("紫霞",22, 169.8));
22 students.add(new Student("至尊宝",26, 165.5));
23 // Collections.sort(students);
24 // System.out.println(students);
25
26 // 4、public static <T> void sort(List<T> list, Comparator<? super T> c): 对List集合中元素,按照比较器对象指定的规则进行排序
27 Collections.sort(students, new Comparator<Student>() {
28 @Override
29 public int compare(Student o1, Student o2) {
30 return Double.compare(o1.getHeight(), o2.getHeight());
31 }
32 });
33 System.out.println(students);
Map接口
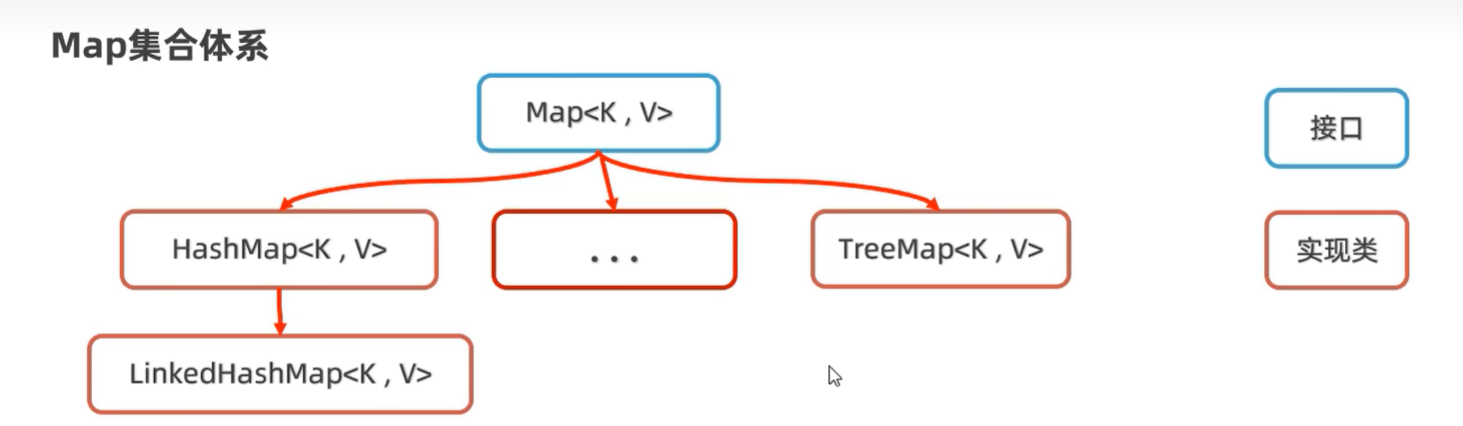
特点(都是由键决定的, 对值没有要求):
- HashMap: 无序, 不重复, 无索引
- LinkedHashMap: 有序, 不重复, 无索引
- TreeMap: 按照大小默认升序, 不重复, 无索引
1 public static void main(String[] args) {
2 // Map<String, Integer> map = new HashMap<>(); // 一行经典代码。 按照键 无序,不重复,无索引。
3 Map<String, Integer> map = new LinkedHashMap<>(); // 有序,不重复,无索引。
4 map.put("手表", 100);
5 map.put("手表", 220); // 后面重复的数据会覆盖前面的数据(键)
6 map.put("手机", 2);
7 map.put("Java", 2);
8 map.put(null, null);
9 System.out.println(map);
10
11 Map<Integer, String> map1 = new TreeMap<>(); // 可排序,不重复,无索引
12 map1.put(23, "Java");
13 map1.put(23, "MySQL");
14 map1.put(19, "李四");
15 map1.put(20, "王五");
16 System.out.println(map1);
17 }
Map的常用方法
- put添加元素: 无序, 不重复, 无索引
- public int size(): 获取集合的大小
- public void clear(): 清空集合
- public boolean isEmpty(): 判断集合是否为空, 为空返回true
- public V get(Object key): 根据键获取对应值
- public V remove(Object key): 根据键删除整个元素(删除键会返回键的值)
- public boolean containsKey(Object key): 判断是否包含某个键 , 包含返回true
- public boolean containsValue(Object value): 判断是否包含某个值
- public Set
keySet(): 获取Map集合的全部键 - public Collection
values(): 获取Map集合的全部值 - putAll把其他Map集合的数据倒入到自己集合中来
1 public static void main(String[] args) {
2 // 1.添加元素: 无序,不重复,无索引。
3 Map<String, Integer> map = new HashMap<>();
4 map.put("手表", 100);
5 map.put("手表", 220);
6 map.put("手机", 2);
7 map.put("Java", 2);
8 map.put(null, null);
9 System.out.println(map);
10 // map = {null=null, 手表=220, Java=2, 手机=2}
11
12 // 2.public int size():获取集合的大小
13 System.out.println(map.size());
14
15 // 3、public void clear():清空集合
16 //map.clear();
17 //System.out.println(map);
18
19 // 4.public boolean isEmpty(): 判断集合是否为空,为空返回true ,反之!
20 System.out.println(map.isEmpty());
21
22 // 5.public V get(Object key):根据键获取对应值
23 int v1 = map.get("手表");
24 System.out.println(v1);
25 System.out.println(map.get("手机")); // 2
26 System.out.println(map.get("张三")); // null
27
28 // 6. public V remove(Object key):根据键删除整个元素(删除键会返回键的值)
29 System.out.println(map.remove("手表"));
30 System.out.println(map);
31
32 // 7.public boolean containsKey(Object key): 判断是否包含某个键 ,包含返回true ,反之
33 System.out.println(map.containsKey("手表")); // false
34 System.out.println(map.containsKey("手机")); // true
35 System.out.println(map.containsKey("java")); // false
36 System.out.println(map.containsKey("Java")); // true
37
38 // 8.public boolean containsValue(Object value): 判断是否包含某个值。
39 System.out.println(map.containsValue(2)); // true
40 System.out.println(map.containsValue("2")); // false
41
42 // 9.public Set<K> keySet(): 获取Map集合的全部键。
43 Set<String> keys = map.keySet();
44 System.out.println(keys);
45
46 // 10.public Collection<V> values(); 获取Map集合的全部值。
47 Collection<Integer> values = map.values();
48 System.out.println(values);
49
50 // 11.把其他Map集合的数据倒入到自己集合中来。(拓展)
51 Map<String, Integer> map1 = new HashMap<>();
52 map1.put("java1", 10);
53 map1.put("java2", 20);
54 Map<String, Integer> map2 = new HashMap<>();
55 map2.put("java3", 10);
56 map2.put("java2", 222);
57 map1.putAll(map2); // putAll:把map2集合中的元素全部倒入一份到map1集合中去。
58 System.out.println(map1);
59 System.out.println(map2);
60 }
遍历
1. 先获取全部键, 再找值
1for (String key : keys) {
2 // 根据键获取对应的值
3 double value = map.get(key);
4 System.out.println(key + "=====>" + value);
5 }
2. 将键值对看做整体遍历
将键值对封装成一个entry对象, 然后用getKey和getValue取里面的键值.
1 // 1、调用Map集合提供entrySet方法,把Map集合转换成键值对类型的Set集合
2 Set<Map.Entry<String, Double>> entries = map.entrySet();
3 for (Map.Entry<String, Double> entry : entries) {
4 String key = entry.getKey();
5 double value = entry.getValue();
6 System.out.println(key + "---->" + value);
7 }
3.Lambda遍历
1map.forEach(( k, v) -> {
2 System.out.println(k + "---->" + v);
3 });
HashMap底层原理
HashMap和HashSet底层原理一模一样, 都是基于哈希表实现, 这是因为Set系列的底层就是基于Map实现, 只是Set只需要键数据, 不需要值数据. 算位置时都是根据键算的, 每个位置放的都是一个Entry对象.
LinkedHashMap底层原理
底层数据结构依然是基于哈希表实现的, 只是每个键值对元素又额外的多了一个双链表的机制记录元素顺序(保证有序). 实际上: 原来学习的LinkedHashSet集合的底层原理就是LinkedHashMap.
TreeMap
TreeMap跟TreeSet集合的底层原理是一样的,都是基于红黑树实现的排序。
TreeMap 集合同样也支持两种方式来指定排序规则
- 让类实现Comparable接口,重写比较规则。
- TreeMap集合有一个有参数构造器,支持创建Comparator比较器对象,以便用来指定比较规则。
Stream流
初识Stream流
使用stream()方法获得流对象, 然后filter过滤, 其中的s表示对每个列表中的元素进行过滤. 最后使用collect方法传入Collectors.toList()将其转化为列表.
1 public static void main(String[] args) {
2 List<String> names = new ArrayList<>();
3 Collections.addAll(names, "张三丰","张无忌","周芷若","赵敏","张强");
4 System.out.println(names);
5 // names = [张三丰, 张无忌, 周芷若, 赵敏, 张强]
6 // name
7
8 // 找出姓张,且是3个字的名字,存入到一个新集合中去。
9 List<String> list = new ArrayList<>();
10 for (String name : names) {
11 if(name.startsWith("张") && name.length() == 3){
12 list.add(name);
13 }
14 }
15 System.out.println(list);
16
17 // 开始使用Stream流来解决这个需求。
18 List<String> list2 = names.stream().filter(s -> s.startsWith("张"))
19 .filter(a -> a.length()==3).collect(Collectors.toList());
20 System.out.println(list2);
21 }
获取Stream流
对于List和Set, 调用stream方法即可. 对于Map, 需要分开键值对, 或者直接调用entrySet得到Entry对象的集合再使用Stream
Arrays和Stream类都提供了静态方法来创建Stream: Arrays.stream(), Stream.of().
这里还使用了Stream的foreach方法对stream进行遍历.
1 public static void main(String[] args) {
2 // 1、如何获取List集合的Stream流?
3 List<String> names = new ArrayList<>();
4 Collections.addAll(names, "张三丰","张无忌","周芷若","赵敏","张强");
5 Stream<String> stream = names.stream();
6
7 // 2、如何获取Set集合的Stream流?
8 Set<String> set = new HashSet<>();
9 Collections.addAll(set, "刘德华","张曼玉","蜘蛛精","马德","德玛西亚");
10 Stream<String> stream1 = set.stream();
11 stream1.filter(s -> s.contains("德")).forEach(s -> System.out.println(s));
12
13 // 3、如何获取Map集合的Stream流?
14 Map<String, Double> map = new HashMap<>();
15 map.put("古力娜扎", 172.3);
16 map.put("迪丽热巴", 168.3);
17 map.put("马尔扎哈", 166.3);
18 map.put("卡尔扎巴", 168.3);
19
20 Set<String> keys = map.keySet();
21 Stream<String> ks = keys.stream();
22
23 Collection<Double> values = map.values();
24 Stream<Double> vs = values.stream();
25
26 Set<Map.Entry<String, Double>> entries = map.entrySet();
27 Stream<Map.Entry<String, Double>> kvs = entries.stream();
28 kvs.filter(e -> e.getKey().contains("巴"))
29 .forEach(e -> System.out.println(e.getKey()+ "-->" + e.getValue()));
30
31 // 4、如何获取数组的Stream流?
32 String[] names2 = {"张翠山", "东方不败", "唐大山", "独孤求败"};
33 Stream<String> s1 = Arrays.stream(names2);
34 Stream<String> s2 = Stream.of(names2);
35 }
Stream流的中间方法
返回的也是stream, 所以支持链式编程.
-
filter: 过滤, 滤出满足条件的元素
-
sorted: 默认升序. 如果是复杂的对象需要提供比较器, 第一个大于第二个返回正数就是升序
(对于小数创建比较器, 由于比较器返回的必须是整数, 因此使用Double.compare方法很便利)
-
limit(long maxSize): 取出前面的maxSize个元素
-
skip(long n): 跳过前面n个元素, 还剩size()-n个元素.
-
map: 映射, 将一个东西用另一个东西来表示.
-
distinct: 去重复, 内部使用hashCode和equals比较.
-
concat: 合并两个流为一个, 两个流里面的元素可以不一样, 返回object流.
1 public static void main(String[] args) {
2 List<Double> scores = new ArrayList<>();
3 Collections.addAll(scores, 88.5, 100.0, 60.0, 99.0, 9.5, 99.6, 25.0);
4 // 需求1:找出成绩大于等于60分的数据,并升序后,再输出。
5 scores.stream().filter(s -> s >= 60).sorted().forEach(s -> System.out.println(s));
6
7 List<Student> students = new ArrayList<>();
8 Student s1 = new Student("蜘蛛精", 26, 172.5);
9 Student s2 = new Student("蜘蛛精", 26, 172.5);
10 Student s3 = new Student("紫霞", 23, 167.6);
11 Student s4 = new Student("白晶晶", 25, 169.0);
12 Student s5 = new Student("牛魔王", 35, 183.3);
13 Student s6 = new Student("牛夫人", 34, 168.5);
14 Collections.addAll(students, s1, s2, s3, s4, s5, s6);
15 // 需求2:找出年龄大于等于23,且年龄小于等于30岁的学生,并按照年龄降序输出.
16 students.stream().filter(s -> s.getAge() >= 23 && s.getAge() <= 30)
17 .sorted((o1, o2) -> o2.getAge() - o1.getAge())
18 .forEach(s -> System.out.println(s));
19
20 // 需求3:取出身高最高的前3名学生,并输出。
21 students.stream().sorted((o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight()))
22 .limit(3).forEach(System.out::println);
23 System.out.println("----------------------------------------------------------------");
24
25 // 需求4:取出身高倒数的2名学生,并输出。 s1 s2 s3 s4 s5 s6
26 students.stream().sorted((o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight()))
27 .skip(students.size() - 2).forEach(System.out::println);
28
29 // 需求5:找出身高超过168的学生叫什么名字,要求去除重复的名字,再输出。
30 students.stream().filter(s -> s.getHeight() > 168).map(Student::getName)
31 .distinct().forEach(System.out::println);
32
33 // distinct去重复,自定义类型的对象(希望内容一样就认为重复,重写hashCode,equals)
34 students.stream().filter(s -> s.getHeight() > 168)
35 .distinct().forEach(System.out::println);
36
37 Stream<String> st1 = Stream.of("张三", "李四");
38 Stream<String> st2 = Stream.of("张三2", "李四2", "王五");
39 Stream<String> allSt = Stream.concat(st1, st2);
40 allSt.forEach(System.out::println);
41 }
Stream流的终结方法
- forEach: 每个进行遍历.
- count: 返回stream里面的元素个数.
- max: 返回装有最大值的一个容(Optional), 必要时提供比较器. 最后使用get()取出
- min: 找最小值. 其余同上
收集Stream流
- collect: 将流处理后的结果收集到一个指定的集合中
- toArray: 收集到一个数组中. 默认是Object数组, 如果希望是其他类型需要显式提供
收集方式:
- Collections.toList()
- Collections.toSet(): 自动去重复, 去重依赖于hashCode和equals.
- Collections.toMap(): 需要提供键和值.
注意, 流只能使用一个, 在被收集之后就关闭了.
1public static void main(String[] args) {
2 List<Student> students = new ArrayList<>();
3 Student s1 = new Student("蜘蛛精", 26, 172.5);
4 Student s2 = new Student("蜘蛛精", 26, 172.5);
5 Student s3 = new Student("紫霞", 23, 167.6);
6 Student s4 = new Student("白晶晶", 25, 169.0);
7 Student s5 = new Student("牛魔王", 35, 183.3);
8 Student s6 = new Student("牛夫人", 34, 168.5);
9 Collections.addAll(students, s1, s2, s3, s4, s5, s6);
10 // 需求1:请计算出身高超过168的学生有几人。
11 long size = students.stream().filter(s -> s.getHeight() > 168).count();
12 System.out.println(size);
13
14 // 需求2:请找出身高最高的学生对象,并输出。
15 Student s = students.stream().max((o1, o2) -> Double.compare(o1.getHeight(), o2.getHeight())).get();
16 System.out.println(s);
17
18 // 需求3:请找出身高最矮的学生对象,并输出。
19 Student ss = students.stream().min((o1, o2) -> Double.compare(o1.getHeight(), o2.getHeight())).get();
20 System.out.println(ss);
21
22 // 需求4:请找出身高超过170的学生对象,并放到一个新集合中去返回。
23 // 流只能收集一次。
24 List<Student> students1 = students
25 .stream()
26 .filter(a -> a.getHeight() > 170)
27 .collect(Collectors.toList());
28 System.out.println(students1);
29
30 Set<Student> students2 = students
31 .stream()
32 .filter(a -> a.getHeight() > 170)
33 .collect(Collectors.toSet());
34 System.out.println(students2);
35
36 // 需求5:请找出身高超过170的学生对象,并把学生对象的名字和身高,存入到一个Map集合返回。
37// Map<String, Double> map = students
38// .stream()
39// .filter(a -> a.getHeight() > 170)
40// .distinct()
41// .collect(Collectors.toMap(a -> a.getName(), a -> a.getHeight()));
42
43 Map<String, Student> map = students
44 .stream()
45 .filter(a -> a.getHeight() > 170)
46 .distinct()
47 .collect(Collectors.toMap(a -> a.getName(), a -> a));
48 System.out.println(map);
49
50 // Object[] arr = students.stream().filter(a -> a.getHeight() > 170).toArray();
51 // Student[] arr = students.stream().filter(a -> a.getHeight() > 170).toArray(len -> new Student[len]);
52 Student[] arr = students.stream().filter(a -> a.getHeight() > 170).toArray(Student[]::new);
53 System.out.println(Arrays.toString(arr));
54 }
我感觉stream编程里面很多都可以使用方法引用, 这时Lambda表达式都多余了. Lambda表达式里面的变量随便设置.
Java高级
反射
获取类的字节码: Class对象
- 静态方法: 类名.class
- 调用Class的方法forName, 填入类的名称
- 调用Object类的方法getClass, 需要现有这个类的对象, 然后: 对象.getClass()
一个类的Class对象只有一个, 不同方式获取的Class对象指向的是同一地址.
1 public static void main(String[] args) throws Exception {
2 Class c1 = Student.class;
3 System.out.println(c1.getName()); // 全类名
4 System.out.println(c1.getSimpleName()); // 简名:Student
5
6 Class c2 = Class.forName("com.itheima.d2_reflect.Student");
7 System.out.println(c1 == c2);
8
9 Student s = new Student();
10 Class c3 = s.getClass();
11 System.out.println(c3 == c2);
12 }
由Class获取类的构造器并初始化对象
属于Class类的方法:
- getConstructors: 获取全部构造器(只能获取public修饰的)
- getDeclaredConstructors: 获取全部构造器(只要存在就能拿到)
- getConstructor(Class<?>): 获取某个构造器(只能获取public修饰的), 需要时填入对应方法对应参数的字节码.
- getDeclaredConstructor(Class<?>): 获取某个构造器(只要存在就能拿到), 需要时填入对应方法对应参数的字节码.
一般就用getDeclaredConstructor(s), 都可以得到.
获取类的构造器的作用是初始化一个对象返回, 下面的Constructor对象的方法:
- T newInstance(Object… initargs): 调用构造器, 传入对应需要的参数, 完成对象初始化并返回.
- setAccessible(boolean): 设置为true, 表示禁止检查访问控制(暴力反射)
构造器有个泛型, 不指定的话返回的都是Object类, 需要强转.
1@Test
2 public void testGetConstructors(){
3 // 1、反射第一步:必须先得到这个类的Class对象
4 Class c = Cat.class;
5 // 2、获取类的全部构造器
6 // Constructor[] constructors = c.getConstructors();
7 Constructor[] constructors = c.getDeclaredConstructors();
8 // 3、遍历数组中的每个构造器对象
9 for (Constructor constructor : constructors) {
10 System.out.println(constructor.getName() + "--->"
11 + constructor.getParameterCount());
12 }
13 }
14
15 @Test
16 public void testGetConstructor() throws Exception {
17 // 1、反射第一步:必须先得到这个类的Class对象
18 Class c = Cat.class;
19 // 2、获取类的某个构造器:无参数构造器
20 Constructor constructor1 = c.getDeclaredConstructor();
21 System.out.println(constructor1.getName() + "--->"
22 + constructor1.getParameterCount());
23 constructor1.setAccessible(true); // 禁止检查访问权限
24 Cat cat = (Cat) constructor1.newInstance();
25 System.out.println(cat);
26
27 AtomicInteger a;
28
29
30 // 3、获取有参数构造器
31 Constructor constructor2 =
32 c.getDeclaredConstructor(String.class, int.class);
33 System.out.println(constructor2.getName() + "--->"
34 + constructor2.getParameterCount());
35 constructor2.setAccessible(true); // 禁止检查访问权限
36 Cat cat2 = (Cat) constructor2.newInstance("叮当猫", 3);
37 System.out.println(cat2);
38
39 }
由Class获取类的成员变量并赋值和取值
属于Class类的方法:
- Field[] getFields(): 获取类的全部成员变量(只能获取public修饰的)
- Field[] getDeclaredFields(): 获取类的全部成员变量(只要存在就能拿到)
- Field getField(String name): 获取类的某个成员变量(只能获取public修饰的)
- Field getDeclaredField(String name): 获取类的某个成员变量(只要存在就能拿到)
获取成员变量是用来赋值和取值, 下面的方法Field对象的
- set(Object obj, Object value): 赋值, 第一个参数是对象实例, 第二个是赋值的内容
- get(Object obj): 取值, 传入对应对象.
- setAccessible: 设置禁止检查访问控制
1 @Test
2 public void testGetFields() throws Exception {
3 // 1、反射第一步:必须是先得到类的Class对象
4 Class c = Cat.class;
5 // 2、获取类的全部成员变量。
6 Field[] fields = c.getDeclaredFields();
7 // 3、遍历这个成员变量数组
8 for (Field field : fields) {
9 System.out.println(field.getName() + "---> "+ field.getType());
10 }
11 // 4、定位某个成员变量
12 Field fName = c.getDeclaredField("name");
13 System.out.println(fName.getName() + "--->" + fName.getType());
14
15 Field fAge = c.getDeclaredField("age");
16 System.out.println(fAge.getName() + "--->" + fAge.getType());
17
18 // 赋值
19 Cat cat = new Cat();
20 fName.setAccessible(true); // 禁止访问控制权限
21 fName.set(cat, "卡菲猫");
22 System.out.println(cat);
23
24 // 取值
25 String name = (String) fName.get(cat);
26 System.out.println(name);
27 }
由Class获取类的成员方法并
属于Class类的方法:
- Method[] getMethods(): 获取类的全部成员方法(只能获取public修饰的)
- Method[] getDeclaredMethods(): 获取类的全部成员方法(只要存在)
- Method[] getMethod(String name, Class<?>… ): 获取类的某个成员方法(只能获取public修饰的), 第一个参数是方法名. 对于某些方法重载, 需要填入参数的字节码对象才能定位.
- Method[] getDeclaredMethod(String name, Class<?>… ): 获取类的某个成员方法(只要存在), 第一个参数是方法名. 对于某些方法重载, 需要填入参数的字节码对象才能定位.
获取类的成员方法是执行方法, 下面是Method类的方法:
- Object invoke(Object, Object… args): 触发某个对象该方法的执行. 第一个参数是对象实例.
- setAccessible: 设置禁止检查访问控制
1 @Test
2 public void testGetMethods() throws Exception {
3 // 1、反射第一步:先得到Class对象。
4 Class c = Cat.class;
5 // 2、获取类的全部成员方法。
6 Method[] methods = c.getDeclaredMethods();
7 // 3、遍历这个数组中的每个方法对象
8 for (Method method : methods) {
9 System.out.println(method.getName() + "--->"
10 + method.getParameterCount() + "---->"
11 + method.getReturnType());
12 }
13 // 4、获取某个方法对象
14 Method run = c.getDeclaredMethod("run"); // 拿run方法,无参数的
15 System.out.println(run.getName() + "--->"
16 + run.getParameterCount() + "---->"
17 + run.getReturnType());
18
19 Method eat = c.getDeclaredMethod("eat", String.class);
20 System.out.println(eat.getName() + "--->"
21 + eat.getParameterCount() + "---->"
22 + eat.getReturnType());
23
24 Cat cat = new Cat();
25 run.setAccessible(true); // 禁止检查访问权限
26 Object rs = run.invoke(cat); // 调用无参数的run方法,用cat对象触发调用的。
27 System.out.println(rs);
28
29 eat.setAccessible(true); // 禁止检查访问权限
30 String rs2 = (String) eat.invoke(cat, "鱼儿");
31 System.out.println(rs2);
32 }
都有setAccessible是因为Constructor, Field, Method类的父类都有AccessibleObject, 里面就有setAccessible.
作用, 应用场景
- 得到一个类的全部成分然后操作
- 可以破坏封装性
- 适合做Java的框架, 基于反射设计通用的功能.
需求: 将对象的字段名和对应的值都保存到文件中
1 // 目标:保存任意对象的字段和其数据到文件中去
2 public static void saveObject(Object obj) throws Exception {
3 PrintStream ps = new PrintStream(new FileOutputStream("junit-reflect-annotation-proxy-app\\src\\data.txt", true));
4 // obj是任意对象,到底有多少个字段要保存。
5 Class c = obj.getClass();
6 String cName = c.getSimpleName();
7 ps.println("---------------" + cName + "------------------------");
8 // 2、从这个类中提取它的全部成员变量
9 Field[] fields = c.getDeclaredFields();
10 // 3、遍历每个成员变量。
11 for (Field field : fields) {
12 // 4、拿到成员变量的名字
13 String name = field.getName();
14 // 5、拿到这个成员变量在对象中的数据。
15 field.setAccessible(true); // 禁止检查访问控制
16 String value = field.get(obj) + "";
17 ps.println(name + "=" + value);
18 }
19 ps.close();
20 }
注解
让别的程序根据注解信息决定怎么执行该程序
自定义注解
1public @interface 注解名称{
2 public 属性类型 属性名() default 默认值;
3}
比如:
1public @interface MyTest1 {
2 String aaa();
3 boolean bbb() default true;
4 String[] ccc();
5}
在其他类使用注解时, 需要添加上这些属性的值:
1@MyTest1(aaa="牛魔王", ccc={"HTML", "Java"})
2// @MyTest2(value = "孙悟空")
3//@MyTest2("孙悟空")
4//@MyTest2(value = "孙悟空", age = 1000)
5@MyTest2("孙悟空")
6public class AnnotationTest1 {
7 @MyTest1(aaa="铁扇公主", bbb=false, ccc={"Python", "前端", "Java"})
8 public void test1(){
9
10 }
11
12 public static void main(String[] args) {
13
14 }
15}
注意: value属性, 如果只有一个value属性的情况下, 使用value属性的时候可以省略value名称不写!! l但是如果有多个属性, 且多个属性没有默认值, 那么value名称是不能省略的.
1public @interface MyTest2 {
2 String value(); // 特殊属性
3 int age() default 23;
4}
注解的原理
注解本质是一个接口, Java中所有注解都是继承了Annotation接口的, 而@注解其实就是一个实现类对象, 实现了该注解以及Annotaion接口.
上面的MyTest1注解经过编译后变成了:
1public interface MyTest1 extends Annotaion{
2 public abstract String aaa();
3 public abstract boolean bbb();
4 public abstract String[] ccc();
5}
元注解
修饰注解的注解
@Target注解: 声明被修饰的注解只能在哪些位置使用
- TYPE: 类, 接口
- FIELD: 成员变量
- METHOD: 成员方法
- PARAMETER: 方法参数
- CONSTRUCTOR: 构造器
- LOCAL_VARIABLE: 局部变量
如@Target(ElementType.TYPE)就只能用在类或接口上, 其余的都不行.
@Retention: 声明注解的保留周期
- SOURCE: 只作用在源码阶段, 字节码文件中不存在
- CLASS(默认): 保留到字节码文件阶段, 运行阶段不存在
- RUNTIME(开发常用): 一直保留到运行阶段
如@Retention(RetentionPolicy.RUNTIME)代码修饰的这个注解运行时也能看到.
1@Target({ElementType.TYPE, ElementType.METHOD}) // 当前被修饰的注解只能用在类上,方法上。
2@Retention(RetentionPolicy.RUNTIME) // 控制下面的注解一直保留到运行时
3public @interface MyTest3 {
4}
1@MyTest3
2public class AnnotationTest2 {
3
4 // @MyTest3
5 private String name;
6
7 @MyTest3
8 public void test(){
9
10 }
11}
注解的解析
判断类上, 方法上, 成员变量上等地方是否存在注解, 并将注解的内容解析出来.
要解析谁上面的注解, 就应先把谁拿到; 解析类上的先拿Class对象, 解析方法上的拿Method对象.
Class, Method, Field, Constructor都实现了AnnotatedElement接口, 它们都有解析注解的能力.
- Annotaion[] getDeclaredAnnotaions(): 获取当前对象上的注解
- T getDeclaredAnnotaion(Class<T> annotaionClass): 获取指定的注解对象
- boolean isAnnotaionPresent(Class<Annotaion> annotaionClass): 判断某个对象上是否存在某个注解
1@Test
2 public void parseClass(){
3 // 1、先得到Class对象
4 Class c = Demo.class;
5 // 2、解析类上的注解
6 // 判断类上是否包含了某个注解
7 if(c.isAnnotationPresent(MyTest4.class)){
8 MyTest4 myTest4 =
9 (MyTest4) c.getDeclaredAnnotation(MyTest4.class);
10 System.out.println(myTest4.value());
11 System.out.println(myTest4.aaa());
12 System.out.println(Arrays.toString(myTest4.bbb()));
13 }
14 }
15
16 @Test
17 public void parseMethod() throws Exception {
18 // 1、先得到Class对象
19 Class c = Demo.class;
20 Method m = c.getDeclaredMethod("test1");
21 // 2、解析方法上的注解
22 // 判断方法对象上是否包含了某个注解
23 if(m.isAnnotationPresent(MyTest4.class)){
24 MyTest4 myTest4 =
25 (MyTest4) m.getDeclaredAnnotation(MyTest4.class);
26 System.out.println(myTest4.value());
27 System.out.println(myTest4.aaa());
28 System.out.println(Arrays.toString(myTest4.bbb()));
29 }
30 }
模拟junit
注解就是标记程序, 让其他程序根据注解信息决定如何对待它们.
1public class AnnotationTest4 {
2 // @MyTest
3 public void test1(){
4 System.out.println("===test1====");
5 }
6
7 @MyTest
8 public void test2(){
9 System.out.println("===test2====");
10 }
11
12 @MyTest
13 public void test3(){
14 System.out.println("===test3====");
15 }
16
17 @MyTest
18 public void test4(){
19 System.out.println("===test4====");
20 }
21
22 public static void main(String[] args) throws Exception {
23 AnnotationTest4 a = new AnnotationTest4();
24 // 启动程序!
25 // 1、得到Class对象
26 Class c = AnnotationTest4.class;
27 // 2、提取这个类中的全部成员方法
28 Method[] methods = c.getDeclaredMethods();
29 // 3、遍历这个数组中的每个方法,看方法上是否存在@MyTest注解,存在
30 // 触发该方法执行。
31 for (Method method : methods) {
32 if(method.isAnnotationPresent(MyTest.class)){
33 // 说明当前方法上是存在@MyTest,触发当前方法执行。
34 method.invoke(a);
35 }
36 }
37 }
38}
动态代理
对象嫌身上干的事太多的话, 可以通过代理转义部分职责
对象有什么方法想被代理. 代理一定要有对应的方法.
规范: 对象想被代理需创建一个对应的接口, 并实现这个接口. 之后代理方法返回的就是这个接口
首先通过Proxy.newProxyInstance创建一个代理对象, 该方法有三个参数. 第三个参数是一个回调函数, 之后之后代理对象完成原本对象方法时会先进入这个回调方法, 我们就在这个回调方法里面做功能添加. 原本方法会返回值就return出去.
创建代理对象的方法:
1public class ProxyUtil {
2 public static Star createProxy(BigStar bigStar){
3 /* newProxyInstance(ClassLoader loader,
4 Class<?>[] interfaces,
5 InvocationHandler h)
6 参数1:用于指定一个类加载器
7 参数2:指定生成的代理长什么样子,也就是有哪些方法
8 参数3:用来指定生成的代理对象要干什么事情
9 */
10 // Star starProxy = ProxyUtil.createProxy(s);
11 // starProxy.sing("好日子") starProxy.dance()
12 Star starProxy = (Star) Proxy.newProxyInstance(ProxyUtil.class.getClassLoader(),
13 new Class[]{Star.class}, new InvocationHandler() {
14 @Override // 回调方法
15 public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
16 // 代理对象要做的事情,会在这里写代码
17 if(method.getName().equals("sing")){
18 System.out.println("准备话筒,收钱20万");
19 }else if(method.getName().equals("dance")){
20 System.out.println("准备场地,收钱1000万");
21 }
22 return method.invoke(bigStar, args);
23 }
24 });
25 return starProxy;
26 }
27}
实体类
1public class BigStar implements Star{
2 private String name;
3
4 public BigStar(String name) {
5 this.name = name;
6 }
7
8 public String sing(String name){
9 System.out.println(this.name + "正在唱:" + name);
10 return "谢谢!谢谢!";
11 }
12
13 public void dance(){
14 System.out.println(this.name + "正在优美的跳舞~~");
15 }
16}
测试
1public class Test {
2 public static void main(String[] args) {
3 BigStar s = new BigStar("杨超越");
4 Star starProxy = ProxyUtil.createProxy(s);
5
6 String rs = starProxy.sing("好日子");
7 System.out.println(rs);
8
9 starProxy.dance();
10 }
11}
应用: 利用代理模式实现AOP, 测试方法耗时.
1public static UserService createProxy(UserService userService){
2 UserService userServiceProxy = (UserService) Proxy.newProxyInstance(ProxyUtil.class.getClassLoader(),
3 new Class[]{UserService.class}, new InvocationHandler() {
4 @Override
5 public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
6
7 if(method.getName().equals("login") || method.getName().equals("deleteUsers")||
8 method.getName().equals("selectUsers")){
9 long startTime = System.currentTimeMillis();
10
11 Object rs = method.invoke(userService, args);
12
13 long endTime = System.currentTimeMillis();
14 System.out.println(method.getName() + "方法执行耗时:" + (endTime - startTime)/ 1000.0 + "s");
15 return rs;
16 }else {
17 Object rs = method.invoke(userService, args);
18 return rs;
19 }
20 }
21 });
22 return userServiceProxy;
23 }